本文综合了网上的文章及本地自行实践踩坑的记录
实测需要有CUDA11及以上版本支持,不然会报错。因此先把显卡驱动安装好。
由于下载Ollama不方便,我把下载好的Windows版本、Linux版本和Linux版本安装脚本修改版本install.sh一起放网盘分享:https://pan.baidu.com/s/1kkr95WOd3fX1sJhAwmPBdQ?pwd=1314
step1:下载Ollama
下载(https://ollama.com/download)并双击运行 Ollama 应用程序。
step2:修改模型下载位置
默认模型下载在C盘,不想占用系统盘的需要修改
关掉ollama之后,设置环境变量
右键我的电脑-属性-高级系统设置,点击“高级系统设置”
在打开的系统属性界面中点击高级-环境变量
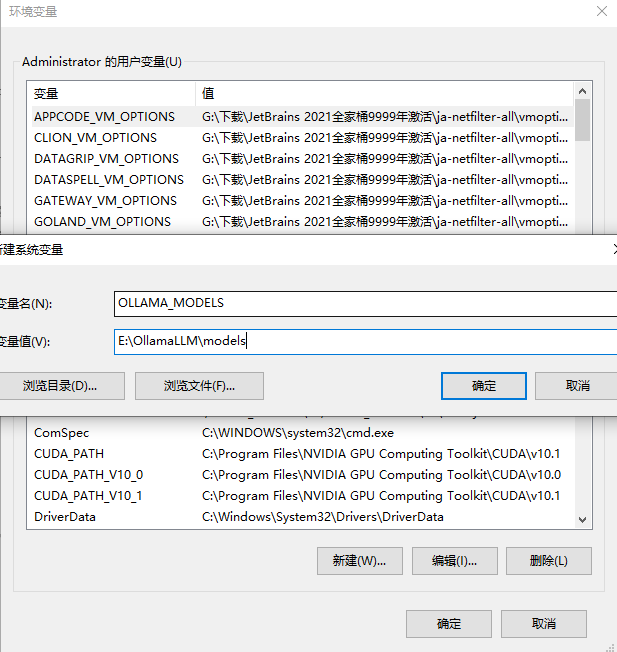
在环境变量界面中点击系统变量中的新建按钮
在跳出来的新建系统变量界面中,变量名设置为:OLLAMA_MODELS,变量值设置为E:OllamaLLMmodels(根据自己想放置的位置),然后点击确定对设置的环境变量进行保存。
step3:验证安装
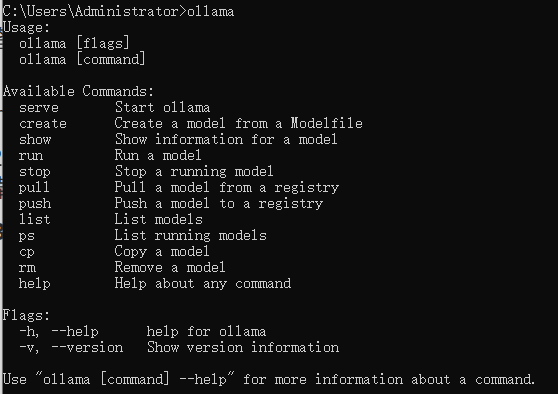
在命令行输入 ollama,如果出现以下信息,说明 Ollama 已经成功安装。
1.2 Linux上使用
如果要在Linux上安装Ollama,可以按照如下方式,我以Ubuntu20.04为例
官网给出的是安装命令,这个命令会从github自动下载安装,但基本由于网络原因失败。
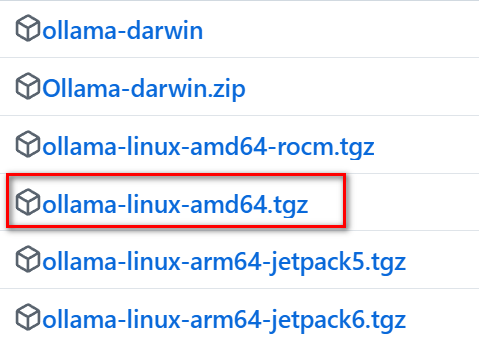
直接访问 ollama github下载最新的版本,目前是0.5.7
先在Linux上确定自己的CPU架构:

下载对应的包:
网上说明是直接解压缩后进行一番设置,这里官方的安装脚本已经写得很好,我们只需要修改原始的安装脚本就可以实现自动安装离线包。
从任意位置下载源码中的离线安装脚本,我这里针对的是最新的0.5.7版本:
Ollama官网
github
gittee加速
原始脚本的第69行到88行如下:
这里我对其中进行注释,并对需要修改的地方进行了说明:
解压缩:
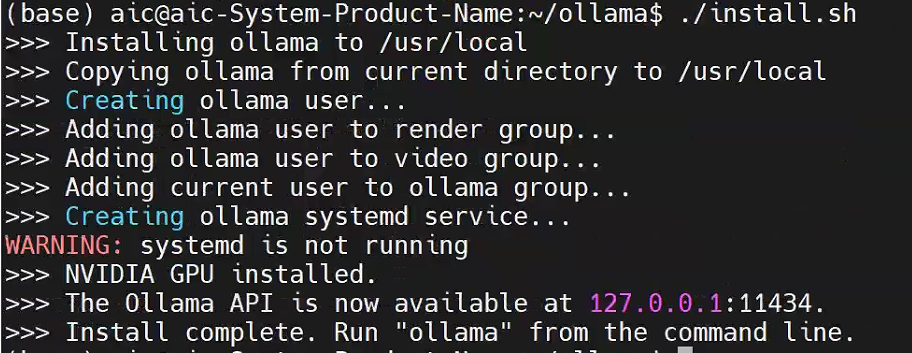
创建ollama-linux-amd64目录并加压缩源码到这个目录,改变install.sh安装脚本执行权限:
直接安装还会报错,原来是每行末尾的回车换行符
,用sed替换后安装:
配置环境变量 指向模型存储目录,修改 :
防火墙放通ollama端口:
启动ollama服务:
停止Ollama服务:
上面的命令形式关闭中断后ollama就停止了,如果想在后台自动运行,可以如下:
接下来就可以进入step4 拉取想要的模型了
跨域访问
如果想让部署在Ubuntu服务器上的ollama能被网络上的其他主机访问,可以修改ollama.service 文件以允许跨域访问:
将文件内容修改为:
重新加载 systemd 守护进程并启用 Ollama 服务:
确认 Ollama 安装成功并运行:
## 2.拉取模型
模型拉取
从命令行,参考 Ollama 模型列表 (https://ollama.com/library)和 文本嵌入模型列表 (https://python.langchain.com/v0.2/docs/integrations/text_embedding/)拉取模型。(拉取模型时,可能比较缓慢。如果出现拉取错误,可以重新输入指令拉取)
结合网上资料,各个版本需要的GPU显存如下:
1.5b 模型,4GB显存就能跑。7b、8b 模型,8GB显存就能跑。14b 模型,12GB显存能跑。32b 模型,24GB显存能跑。
我尝试了一下1.5B和7B
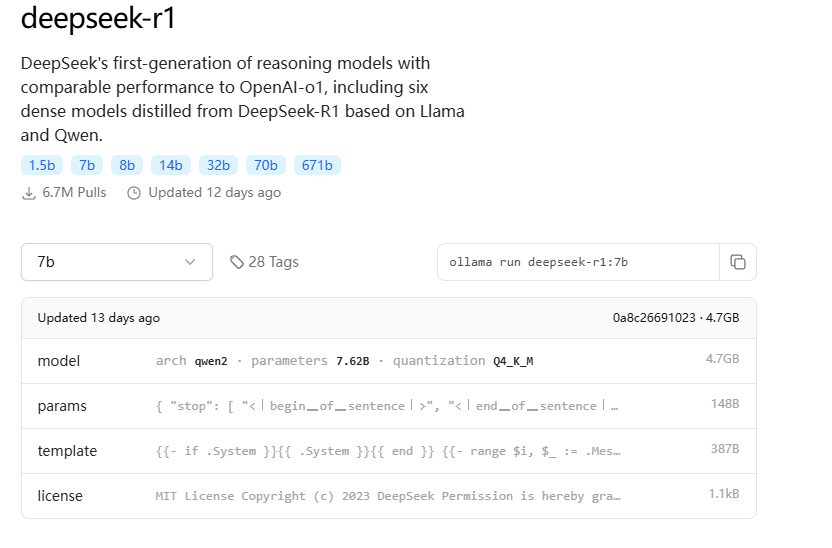
命令行输入下面的命令会自动拉取模型。对于GPU小的的可以玩下1.5b(模型文件约1.1GB)
如果>8GB显存可以尝试7B(模型文件约4.7GB)
拉取完毕后查看模型列表
我下载了1.5b和7b模型:
查看正在运行的模型
如果要删除模型
拉取完成后就可以直接聊天了:
 telegram最新中文的下载网址在哪呢
telegram最新中文的下载网址在哪呢
step1: 通过Google应用商店在Google浏览器中安装page Assist插件:
Step2:选择本地搭建的模型,点击配置按钮,设置中文

step3:RAG设置,模型选择本地搭建的

到了这一步,也可以进行聊天对话了

更好的是可以联网,突破本地的局限性:最新官网的telegram下载的地址在哪呢

step4:点击左侧管理知识,可以添加本地知识库。
填写知识标题及上传文件,点击提交按钮。
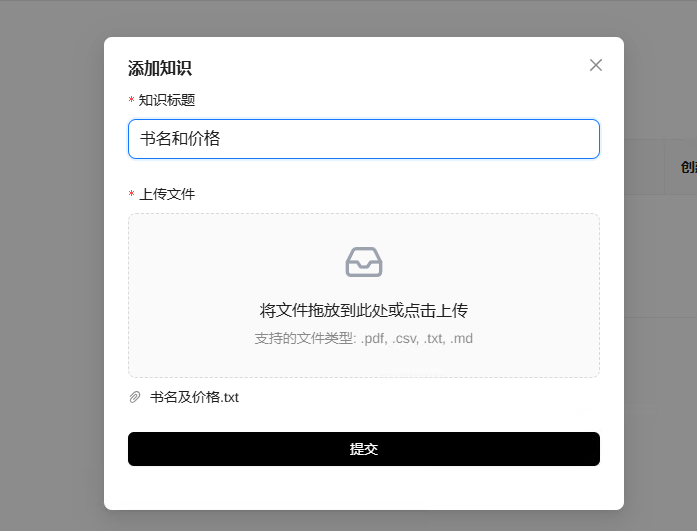
我提供的书名及价格文件只是简单的内容,自己知识库可以搭建更加复杂的内容
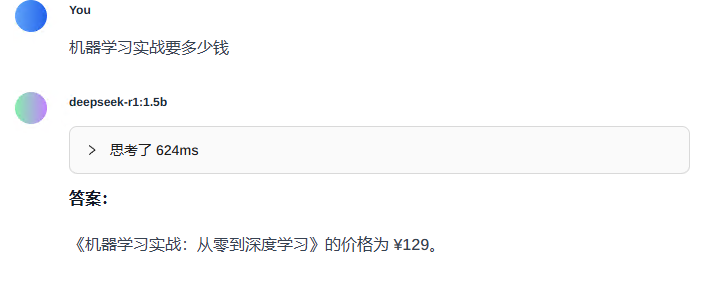
新建聊天进行测试,在聊天窗口要记得点击右下角知识,选择刚才搭建的知识库名称,然后在上方看到就可以了。
对模型进行测试,看看是否可以根据知识库进行回答。
4.1 Pycharm接入本地官网最新版的telegram下载的地方是什么
在Pycharm中找到文件(File)-设置(Settings)-插件(Plugins),输入CodeGPT,即可点击安装(Install)即可:
中文最新版telegram下载的网站
安装后重启Pycharm,打开CodeGPT配置
在 CodeGPT 的设置界面中,找到与 或 相关的配置选项。
确保 Ollama 已正确安装并运行
在设置界面中选择 ,找到 。
在 中选择刚刚安装的 模型。
点击 或 保存设置。

下面就可以愉快的在PyCharm中使用最新的官网telegram下载地方-r1加速编程学习了,左侧是代码编辑界面,右侧是r1大模型,直接对话式提问,省去了来回不同页面折腾的麻烦:
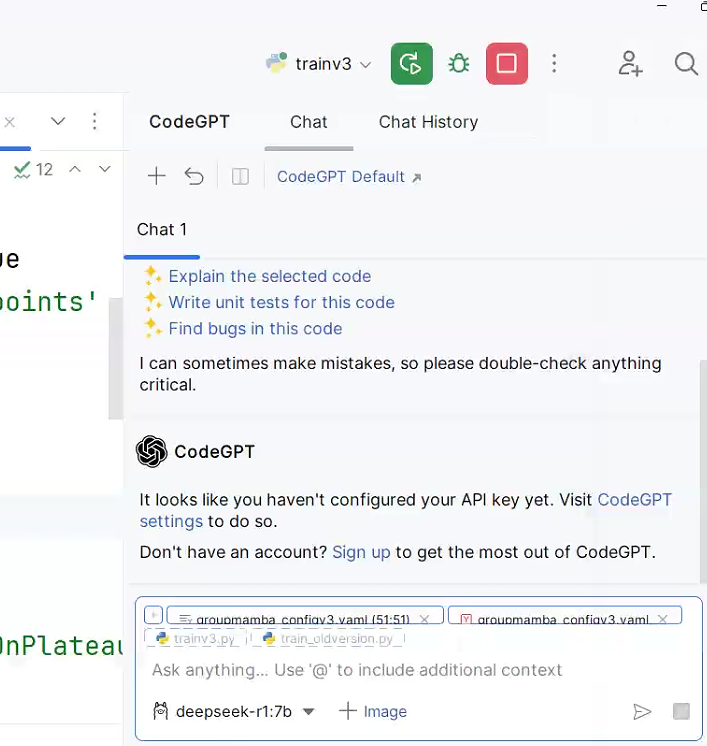
大家再感受最新的官网telegram下载地方-r1:1.5b大模型的回复延时,几乎1秒钟响应,本人电脑是32GB内存,11GB显存,这响应速度可以了。CodeGPT插件显示了Tokens数,有些同学担心这是不是在计费?不是的!只是一个数字统计,无任何费用,因为使用的是本地自己电脑的算力。
另外,CodeGPT应该是目前大模型+编程UI做的最好的插件了,感兴趣的同学可以根据以上步骤安装试试。
4.2 VSCODE中接入本地最新的官网telegram下载地方
VSCODE应用商店中搜索进行安装
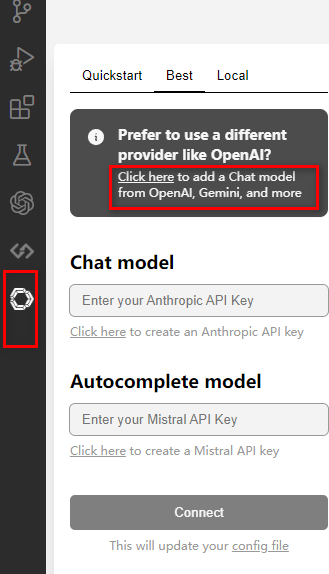
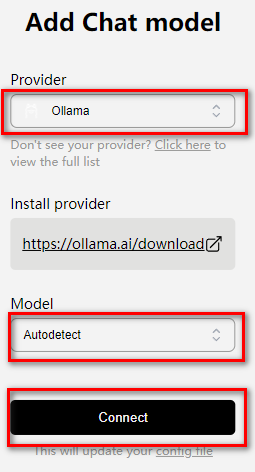
选择模型:

可以开始用了:
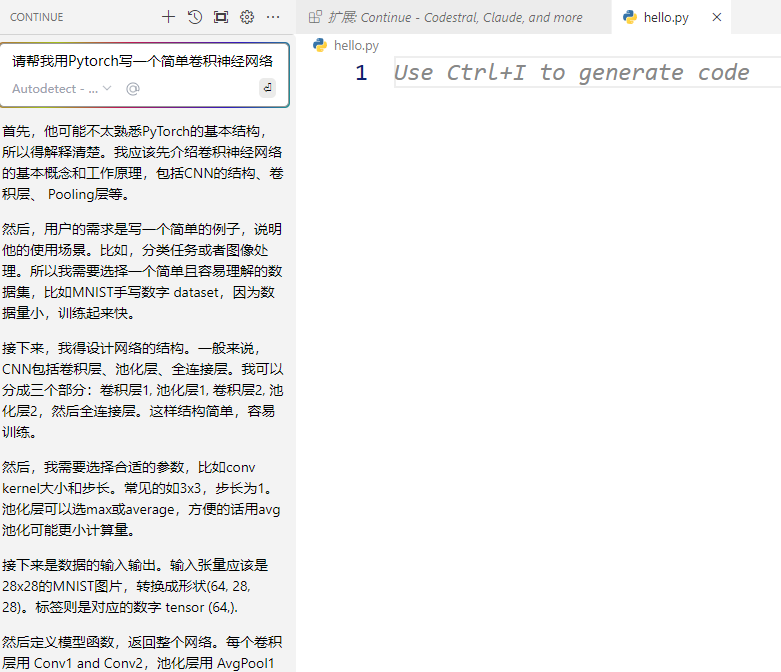
5. 本地最新的官网telegram下载地方接入Word
配置word
新建一个Word文档,点击 文件 -> 选项 -> 自定义功能区,勾选“开发者工具”。

点击 信任中心 -> 信任中心设置,选择“启用所有宏”与“信任对VBA…”。

接下来点击确定,我们发现选项卡中出现了“开发者工具”,点击开发者工具,点击Visual Basic,将会弹出一个窗口。

我们点击新窗口中的插入,点击模块。

点击后将会弹出一个编辑器,把如下代码复制到编辑区中。
完成后,可直接关闭弹窗。
点击 文件 -> 选项 -> 自定义功能区,右键开发工具,点击添加新组。
精简版telegram下载的地址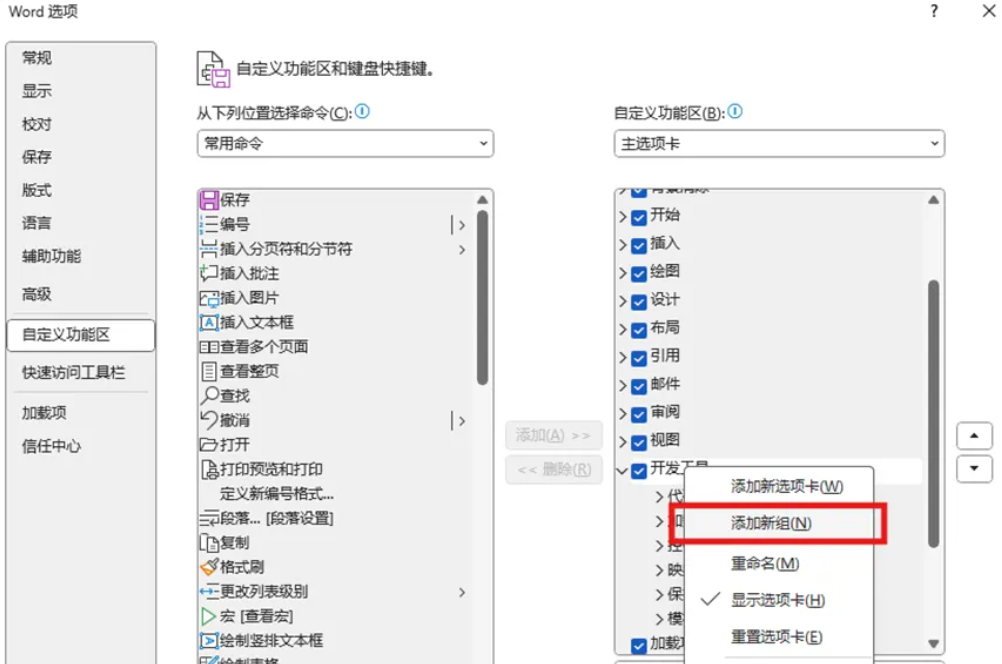
在添加的新建组点击右键,点击重命名。将其命名为官网最新版的telegram下载的地方是什么,并选择心仪的图标,最后点击确定。
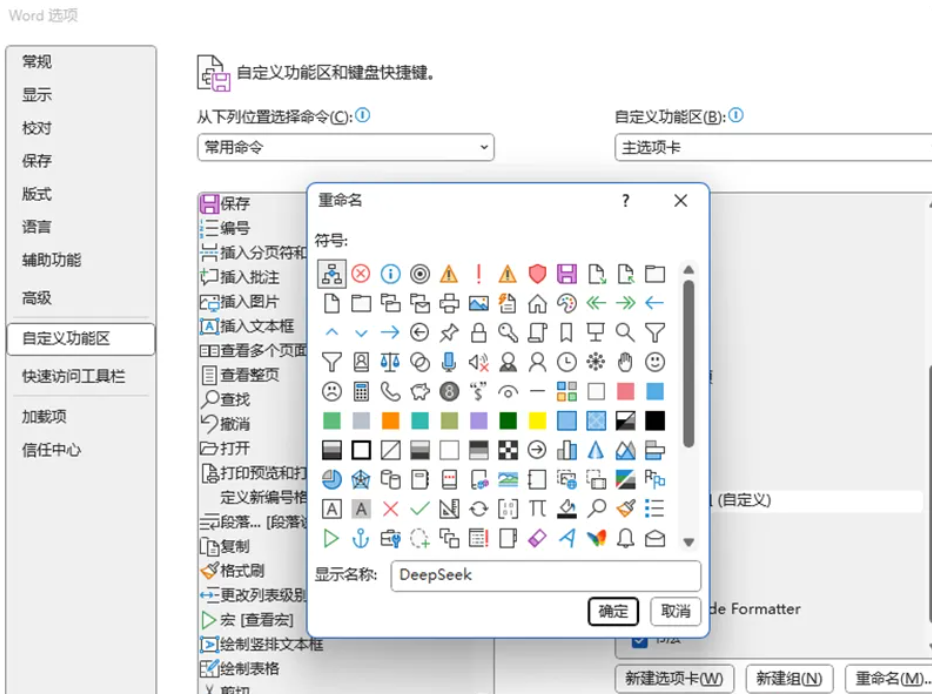
首先选择最新的官网telegram下载地方(自定义),选择左侧的命令为“宏”,找到我们添加的最新的官网telegram下载地方V3,选中后点击添加。
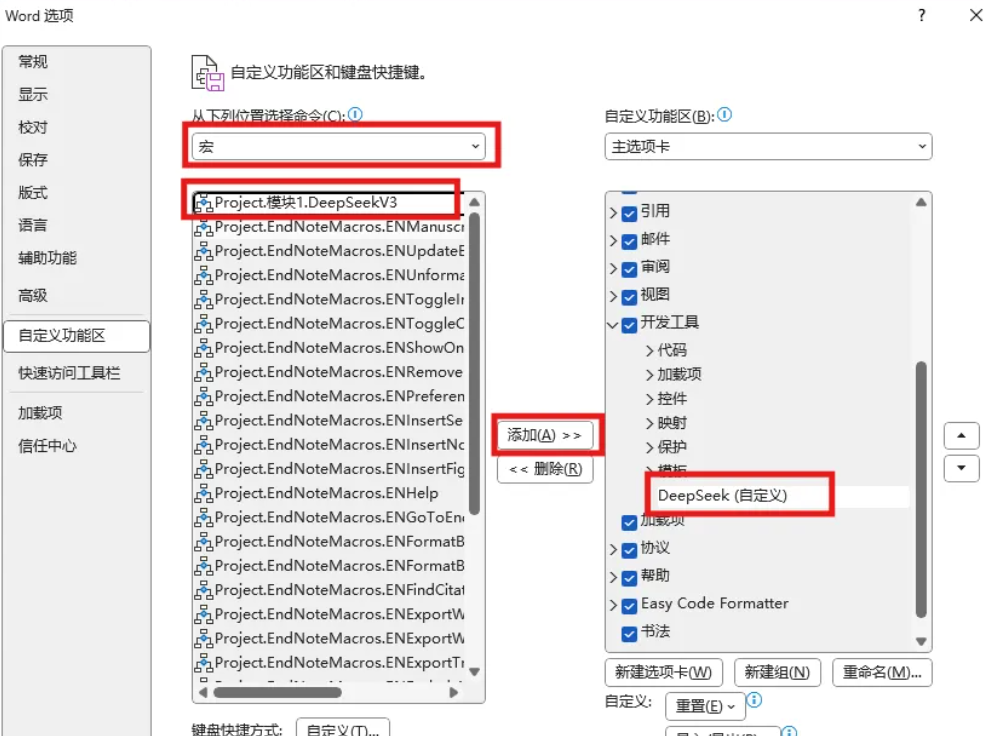
随后,选中添加的命令,右键点击重命名,选择开始符号作为图标,并重命名为“生成”。
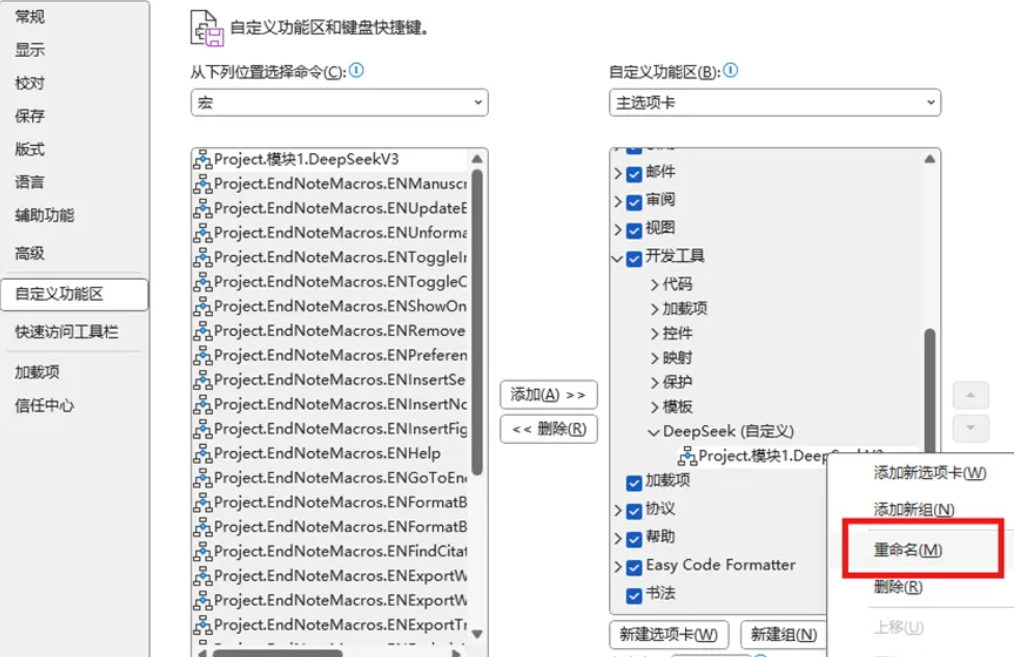
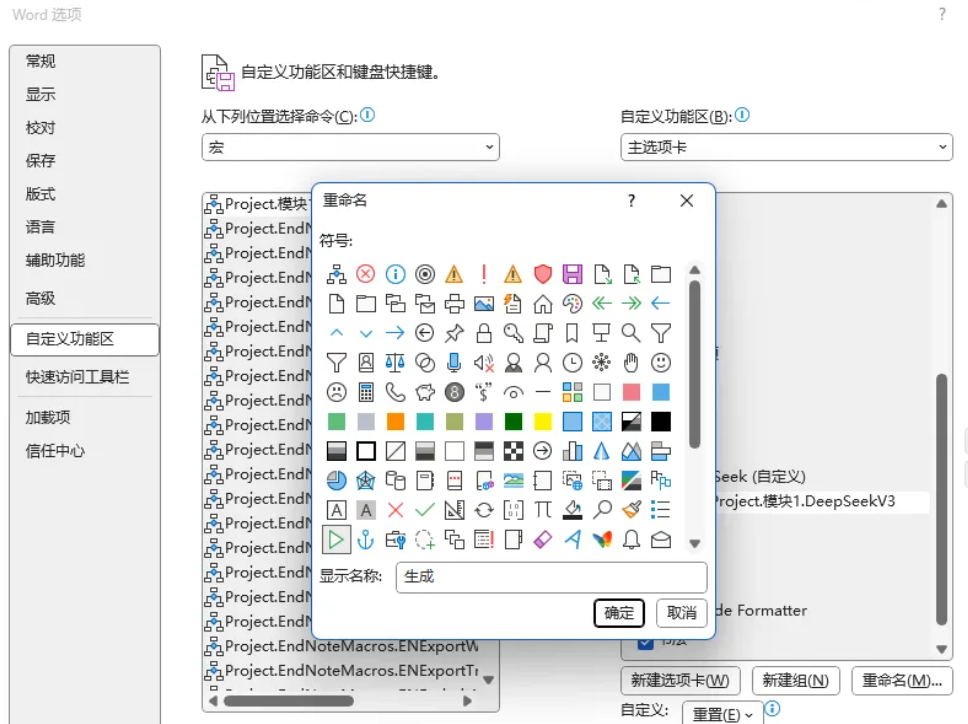
最后点击确定。
至此,Word成功接入最新的官网telegram下载地方大模型。
选中文字,点击生成,就可以直接将选中的文本发送给大模型,大模型将会按照你选中的文本,做出响应。
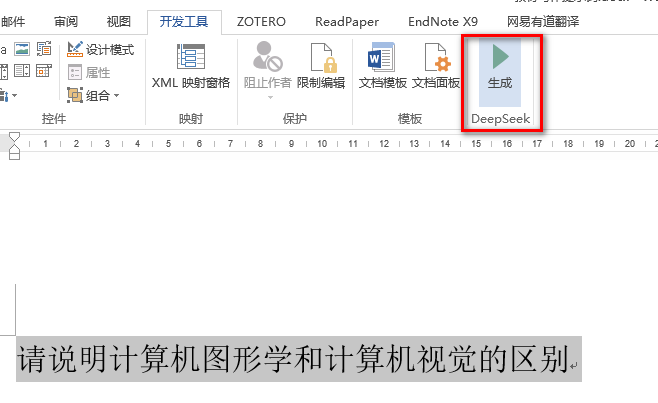
生成效果如下:

为确保配置后的宏不会消失,配置如下:
点击 开发工具 -> 宏。
.
选中我们配置的最新的官网telegram下载地方V3,点击管理器。
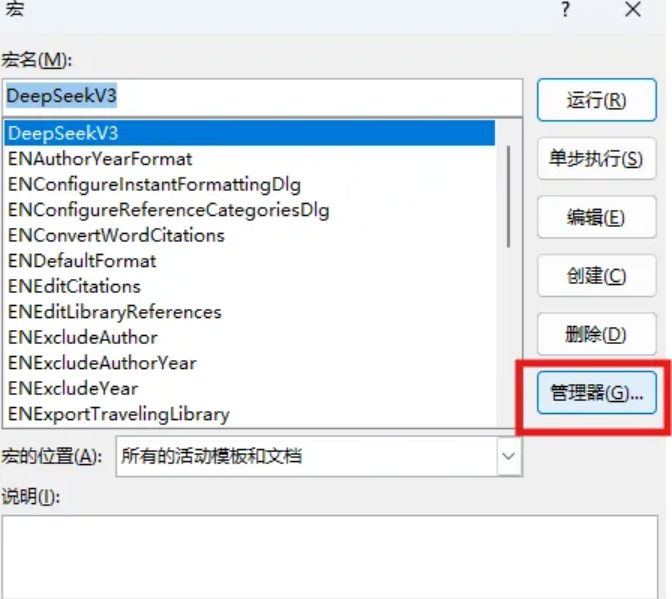
选中左侧的模块1,点击复制,右侧将会出现模块1,最后点击关闭。
问题顺利解决,再次重启word后,不会出现宏消失的问题。
这部分接入需要官网最新版的telegram下载的地方是什么 API Key的支持,但是目前官方暂停了KEY申请,等恢复后补上。应该和本地接入差不多,只是把URL那里换成了官方的key。